
Data management is our largest and most diverse area of research. We divide our activities into four activity streams: Cloud Native Systems, Blockchain & Distributed Ledger Technology, Consensus Mechanisms, and Graph Data Processing.
While all four streams are distinct, we create synergies across domains by developing scalable approaches that often incorporate interdisciplinary research.
Our research aims to improve the efficiency of analytical queries within in-memory OLAP databases. The challenge in this scenario is the concurrent execution of multiple analytical queries, often redundantly processing the same tasks and generating identical data. Analytical queries, known for their prolonged execution and resource-intensive operations on extensive datasets, compound the issue as their numbers increase, leading to heightened concurrent outstanding computations, longer response times, and diminished throughput.Our proposal to this problem entails an online system that actively recognizes and leverages real-time overlaps in both work and data in a collaborative manner to enhance the overall throughput of the OLAP database. To do so, our system is geared toward identifying potential sharing opportunities among concurrent queries by strategically orchestrating their execution, prioritizing sharing dynamics to significantly boost throughput.
Also in our research on blockchains, DLT, and consensus we aim to optimize performance, maximize throughput, and achieve a high degree of functional safety.
More precisely, we aim to develop 3H distributed systems (i.e., high-performance, highly scalable, and highly available), providing both general and tailored consensus algorithms, fault tolerance, and consistency models to support various distributed applications, such as blockchains, databases, cloud computing, and distributed training systems.
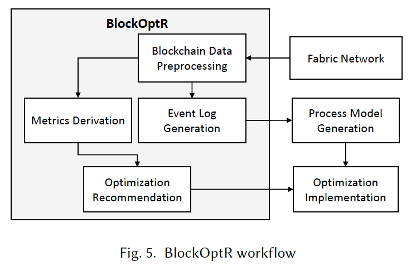
Complementing these efforts we work on heuristic approaches to performance optimization of distributed ledger technologies, focus on improving the throughput, latency, and success rate of the Hyperledger Fabric network. This is done by experimental analysis of transaction failures, development of a threshold-based performance optimization recommendation system, and an ongoing development initiative of a self-adaptive blockchain system (BlockOptR).
Conflict Free Replicated Data Types (CRDTs) are novel solutions to achieve eventual consistency in data replication. Completed and ongoing studies with improving CRDTs such as enchanting CRDTs with reversibility, and incorporating Byzantine Fault Tolerance with CRDTs. New distributed algorithms are developed to accommodate the requirements.
For distributed graph processing, a graph needs to be partitioned into smaller parts that are distributed among the machines of a compute cluster. Then, distributed graph processing can be performed. In the past decade, different graph partitioning algorithms have emerged that influence the performance of distributed graph processing workloads. However, it is a challenging task to select the best graph partitioner for a given input graph and graph processing workload. In our work, we propose a machine learning-based approach for automatic graph partitioner selection.

Professor
Toronto, Canada

PhD Student
Toronto, Canada

PhD Student
Toronto, Canada

PhD Student
Toronto, Canada

PhD Student
Toronto, Canada

PhD Student
Toronto, Canada

PhD Student
Munich, Germany
PhD Student
Munich, Germany

PhD Student
Munich, Germany

Undergraduate Student
Toronto, Canada